How I learned to upsert Millions of Documents into MongoDB with minimal overhead
How I learned to upsert Millions of Documents into MongoDB with minimal overhead
TL;DR
I efficiently manage millions of documents in Mongodb using Mongoose on an express node.js server, ensuring minimal CPU and memory load.
The Problem
To very vaguely describe the problem: What I was supposed to do is figure out a way to handle the upsertion of millions of documents of data. Although we were never gonna get a million documents, it was never too bad to always prepare for the worst case scenario. The upsertion process was part of a flow where huge csv file data gets parsed, sanitized, validated and then finally upserted into our database (where some other csv data already has existed/or not).
Airing the first thoughts
The first thought immediately was that using collection.insertMany(). Had good discussion forums backing it and clearly it was better than something like collection.insertOne() discussion for thousands of records at a time because each of the operations needs to be acknowledged v/s some really large batches of them at a time.
Reference: MongoDB Community Forum - insertOne vs insertMany Discussion
I could simply just throw in as many documents I'm getting into the insert many times. It will internally take care of the batching and I would not have to do anything, but is it the best way to do it? Is there more performance that could be theoretically squeezed out of it?
Lets look at optimization before I build?
Maybe not the best way to go about thinking about optimizations. How do optimizations work? First you build a system that you want to build, you use it for a good amount of time and with time you start running into these storms or fog that slows you down.
Your systems are overwhelmed, that is creeping into your PMs knowledge, which is creeping into your managers knowing about it and finally the end users draw the axe. And then is when you start thinking about optimizing the system and yes, many would argue, that would be the right time thinking about optimization but I went ahead to start searching for all the ways people have messed up "Inserting/Upserting/Updating millions of records into mongodb"", to avoid their pitfalls.
I started going onto stack overflow to understand the common issues people face while using these MongoDb methods and common bottlenecks that the people complain about because at end of the day I wasn't doing anything new and all the problems that they faced, I was certainly going to face down the line, so the sooner we dealt with it, the better.
So I start…
I set a scope myself, I want to ideally support update / upsert of about 1 million row documents at a time.
But no, I want 15 million, or even 100 million if possible. Be the fastest and fattiest solution possible that can handle anything you throw at it with the most amount of operations supported. I expected nothing less.
So I start charting up as a solution, trying to find the best ways to churn out the most out of the system.
The core of it is very simple, utilizing bulk operations, to go absolute raw with as little abstractions between database and us as possible
TOTAL_RECORDS = 1_000_000_000
BATCH_SIZE = 10_000
NUM_CORES = available_cpu_cores
RECORDS_PER_CORE = TOTAL_RECORDS / NUM_CORES
for each core_index in 0 to NUM_CORES:
start worker with:
start_index = core_index * RECORDS_PER_CORE
end_index = (core_index + 1) * RECORDS_PER_CORE
batch_size = BATCH_SIZE
// Inside each worker:
connect to MongoDB
for i from start_index to end_index step batch_size:
ops = []
for j from 0 to batch_size:
id = i + j
ops.append:
upsert document with _id = id
set fields = { value: "val-id", timestamp: now }
bulk write ops (unordered)
disconnect
With the bulkwrite ops passing it the custom config of:
{
ordered: false, // Disable ordering
writeConcern: { w: 0, j: false } // No acknowledgement, no journaling
}
Reference: MongoDB Manual - Bulk Write Operations
So we went absolutely bonkers, it does the operations through bulk-write (what insertMany or updateMany uses under the hood in many of the mongoDb drivers), we skipped getting any acknowledgements, we utilized worker threads, we removed the order in which they need to be written, because we don't care, we only care about the absolute best performance.
The result of the initial attempts?
Fast? for sure, but it was taking up all the resources available … when I say all resources, I literally mean all of the resources. The CPU usage was touching 100% and so was the memory. We were testing this on our local laptop setups and it certainly wasn't desirable for a server setup even. It was blocking each and every other process on the system. We had to build something that would not be a hindrance
Putting learnings to use
Going as fast as possible maybe sound and seem good but isn't always the right way to go about things and I learnt more about this from Dmytro Harazdovskiy's article on updating 63 million records in MongoDB 50% faster, putting most of my faith in his findings. Just going through his entire article in the first glance gives many valuable insights, such as:
- Don't go all bonkers
- Be mindful of the resources utilized
- Graph and test everything, keep looking at metrics
- TEST ITERATE TEST ITERATE TEST ITERATE
Dmytro's blog shines a good light into some of the custom config we have written for the bulk write operation. It shows the gradual improvements made in choosing the right set of tools.
However, my biggest takeaway from the articles he wrote is the use of cursor. The use of collection.cursor() flipped the switch on me and prompted me to use a combination of cursor, batching, parallel writes and leveraging built-in mongoDb configs for good performance with minimal overheads.
A learnt man, a better man
I started charting my new implementation, because that is what good engineers do. And so I pulled up my excalidraw and came up with this abomination of a flow or overview, whatever you wanna call it.
System Architecture Flow Diagram
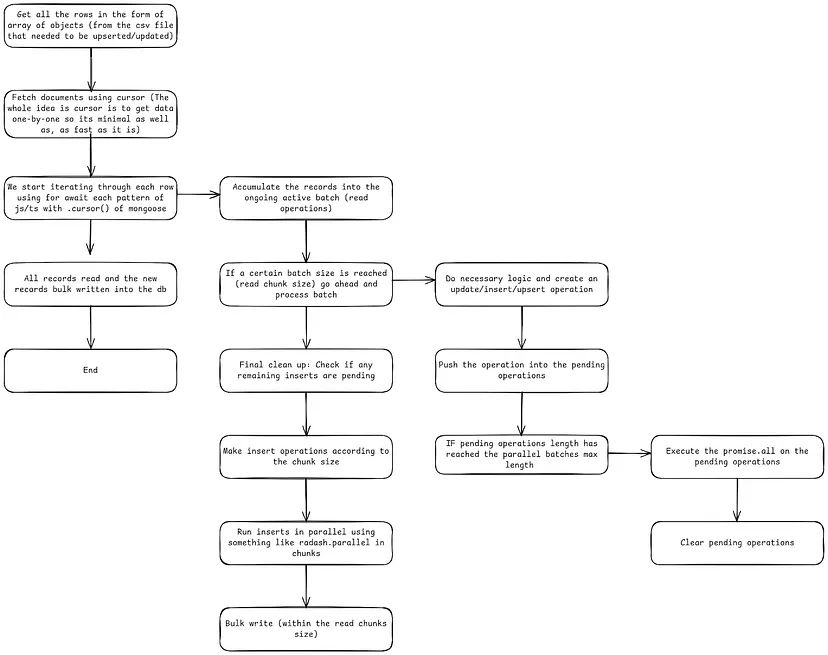
If this was any confusing, or if you too lazy to read, and need the closest to a tiktok version of it, another overview to understand the jists
 Might look at this and suddenly think that the read chunks are probably the bottleneck but no, you can adjust the sizes according to your own needs, that's the whole point of modularizing the process so much. That at any given moment, you can tweak the size of the pipelines that suits the data you want to read and upsert into.
Might look at this and suddenly think that the read chunks are probably the bottleneck but no, you can adjust the sizes according to your own needs, that's the whole point of modularizing the process so much. That at any given moment, you can tweak the size of the pipelines that suits the data you want to read and upsert into.
But where is the script?
I know, you need the script to chug it into your smart word predictors that you call AI and coding LLMs and so I will talk about the script, the holy grail, the code now.
I have removed many parts from this and renamed stuff to avoid any direct business logic from leaking into the script. This should however give you a good idea of how the system is designed and how it works.
async function upsertLargeDataset(records) {
try {
const dbCollection = MongoModels.someCollection;
const dataMap = new Map(
records.map(item => [item.id, { ...item }])
);
let tempReadBatch = [];
let parallelTasks = [];
const stream = dbCollection.find({}).lean().cursor();
for await (const doc of stream) {
tempReadBatch.push(doc);
if (tempReadBatch.length >= READ_CHUNK) {
parallelTasks.push(
handleExistingDocs(tempReadBatch, dataMap, dbCollection)
);
tempReadBatch = [];
if (parallelTasks.length >= PARALLEL_BATCHES) {
await Promise.all(parallelTasks);
parallelTasks = [];
}
}
}
if (tempReadBatch.length > 0) {
parallelTasks.push(
handleExistingDocs(tempReadBatch, dataMap, dbCollection)
);
}
if (parallelTasks.length > 0) {
await Promise.all(parallelTasks);
}
if (dataMap.size > 0) {
const bulkInserts = Array.from(dataMap.values()).map(doc => ({
insertOne: { document: { ...doc } }
}));
const insertChunks = chunk(bulkInserts, UPDATE_CHUNK_SIZE);
await radash.parallel(PARALLEL_BATCHES, insertChunks, async (chunk) => {
await dbCollection.bulkWrite(chunk, {
ordered: false,
bypassDocumentValidation: true,
writeConcern: 0,
});
});
}
} catch {
throw new Error("Upsert operation failed");
}
}
async function handleExistingDocs(docs, map, col) {
const operations = [];
for (const doc of docs) {
const incoming = map.get(doc.id);
if (!incoming) continue;
operations.push({
updateOne: {
filter: { id: doc.id },
update: { $set: incoming },
upsert: true
}
});
map.delete(doc.id);
}
if (operations.length === 0) return;
const updateChunks = chunk(operations, UPDATE_CHUNK_SIZE);
await radash.parallel(PARALLEL_BATCHES, updateChunks, async (chunk) => {
await col.bulkWrite(chunk, {
ordered: false,
bypassDocumentValidation: true,
});
});
}
Who is gonna explain the script?
Another easy LLM pastable instructions would be these:
1. Start streaming existing documents from the database using a MongoDB cursor to handle large data efficiently.
2. Collect documents in batches (up to READ_CHUNK size) as they stream in.
3. For each full batch:
- Schedule a parallel task (up to PARALLEL_BATCHES at a time).
- Each task checks if any documents in the batch have a matching incoming record.
- If matched, prepare an upsert (update or insert).
- Remove matched items from the map so they are not inserted later.
4. After all streaming is done, process any remaining batch and wait for all parallel tasks to finish.
5. Whatever is left in the map are new records (not seen in DB), so bulk insert them in chunks (UPDATE_CHUNK_SIZE) using unordered, parallel writes.
6. All operations (updates and inserts) are done using MongoDB's `bulkWrite` API with `ordered: false` for better performance and fault tolerance.
💡 Quote Of The Day: The best fault tolerance systems are the ones that do not recognize anything as a fault in the system and such is our bulkwrite final operation.
But on a serious note, reasons why we have baked something like that in our system are:
- The csv data we parse is pretty simple
- The data is thoroughly validated and sanitized through many steps that come before coming to this process
- Any real faults while writing to database would be because of some outages, connections errors or something and it would really never be bad data or overlooked edge case because there are none
- We are ready to cross the bridge when it comes to that and in that case too it will be pretty simple for us to mitigate
Lessons learnt
- Avoid premature optimization; build, test, then optimize based on bottlenecks.
- Use bulkWrite with ordered: false for efficient upserts and if you know its short falls too, it does contribute much lesser than other steps taken, but yes, does help to squeeze performance
- Use cursors (collection.find().cursor()) for large datasets.
- Process data in manageable chunks (Different for reads and updates accordingly)
- Parallelize tasks wherever you can
- Disable unnecessary validations and acknowledgments if data is pre-validated.
- Continuously track CPU and memory usage to protect other processes. And make useful metric findings like how Dmytro did, I was too lazy to collect it back for this but yes, I did some observations
- Test and refine batch sizes, parallel limits based on performance metrics. Try to build a dynamic system if possible which self adjusts these things according to situations
- You will find all sorts of crazy options available with databases, but your system design is more important.
What have I achieved?
Time? As minimal as it could be, Memory? As minimal as it could be, CPU? As minimal as it could be. We don't want to have an absolutely fast system, we want a system that would not absolutely overwhelm other systems on the same server, we want it to take only a reasonable amount of time for the process. A balanced approach is always better than the fastest available approach.
Required References:
-
MongoDB Community Forum - Updating 100s of Millions of Documents
This is where it all started - got the initial idea about using bulk write operations with updateOne operations. Sometimes the best ideas come from community discussions! -
How to update 63 million records in MongoDB 50% faster?
Dmytro's second blog was absolutely pivotal - it not only helped shape the script but also directly influenced how I structured the entire solution. The parallel processing and performance optimization techniques were gold! -
Optimizing massive MongoDB inserts
Dmytro's first blog that opened my eyes to how large-scale operations are handled in MongoDB. It's like reading the prequel to understand the whole story better. -
MongoDB Community Forum - Iterable Cursor Issues in NodeJS
This discussion about MongoDB's cursor implementation was crucial in understanding how to properly stream documents without overwhelming memory. -
MongoDB Node.js Driver - Cursor Documentation
The official docs on asynchronous cursor in Node.js - because sometimes you need to go straight to the source to understand how to properly implement cursor-based operations.
And a bunch of stack overflows and other articles that I have read and forgot to add here but you can search them around, should be enough to get you started.
Thanks for reading! If you have any questions or feedback, please feel free to reach out to me. Also ready to geek out on these things if you have some information to share.